ORACLE之视图和系统函数
视图
视图是什么?
视图(View)是从一个或多个表(或视图)导出的表。视图与数据库中的物理表不同,视图是一个虚表(它的本质是一个SQL查询),即视图所对应的数据不进行实际存储,数据库中只存储视图的定义,在对视图的数据进行操作时,系统根据视图的定义去操作与视图相关联的基本表。
视图有什么作用?
安全性:限制数据访问
(通过视图来访问数据表,仅返回指定的数据)查询简化、结构简化:使得复杂的查询容易
(将经常使用的SQL复杂查询,创建为视图,通过查询视图和SQL语句的结合,达到相同的效果)- 与更改隔离:提供数据的独立性(例如: 如果应用建立在数据库表上,当数据库表发生变化时,可以在表上建立视图,通过视图屏蔽表的变化,从而应用程序可以不动)
- 便利性:表现相同数据的不同观察
- 数据完整性
语法
1 | create or replace view V_viewname |
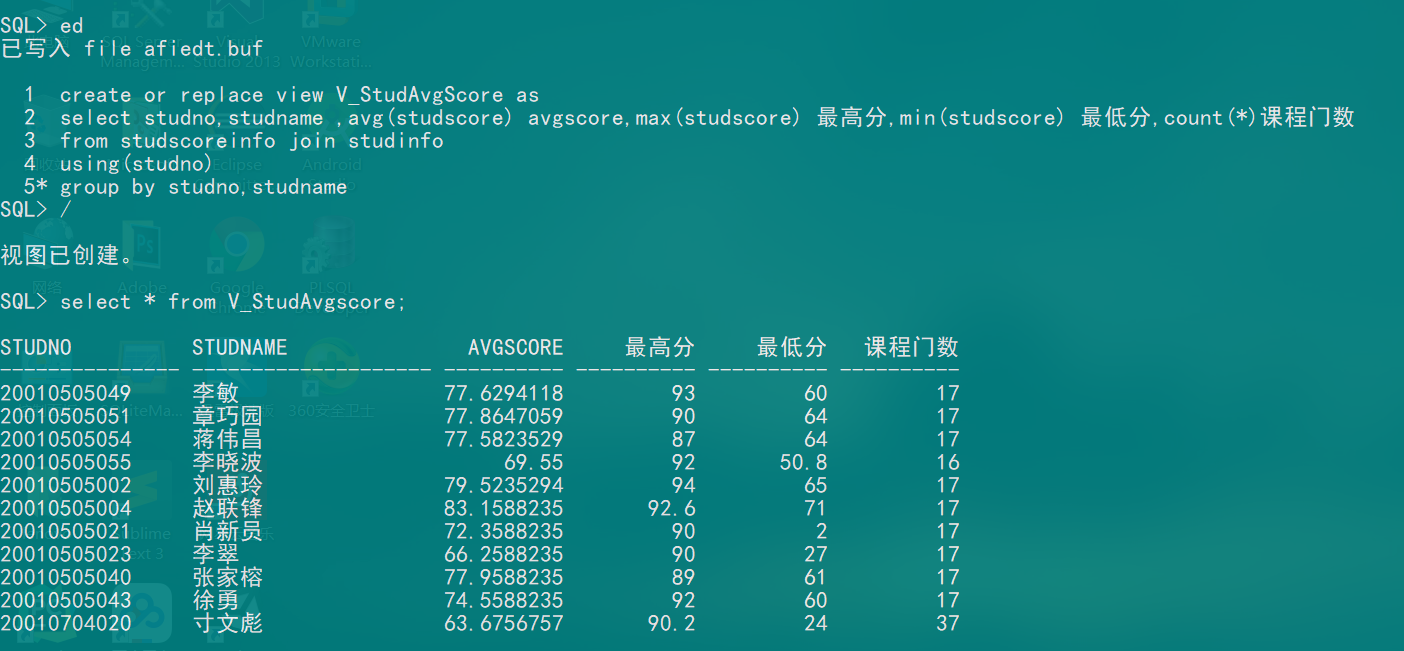
- 示例:创建学生平均成绩视图(ViewStudAvgScore)其中包括学生学号、学生姓名、平均分、总分 、 最 高 分 、 最 低 分 、 课 程 门 数 ,即(StudNo,StudName,AvgScore,SumScore,MaxScore,MinScore,CountCourse)字段。
1 | create or replace V_StudAvgScore as |
- 使用视图
1 | select * from V_StudAvgScore |
序列
什么是序列?
序列(SEQUENCE)是序列号生成器,可以为表中的行自动生成序列号(经常与触发器配合使用,从而实现ID的自动增长),产生一组等间隔的数值(类型为数字)。不占用磁盘空间,占用内存。其主要用途是生成表的主键值,可以在插入语句中引用,也可以通过查询检查当前值,或使序列增至下一个值。
语法
创建序列
1 | create sequence [sequencename] |
- 补充
1.最大值和最小值可以不指定,最简单的序列指定步长和初值就可以了;
2.CYCLE和NOCYCLE 表示当序列生成器的值达到限制值后是否循环。CYCLE代表循环,NOCYCLE代表不循环。如果循环,则当递增序列达到最大值时,循环到最小值;对于递减序列达到最小值时,循环到最大值。如果不循环,达到限制值后,继续产生新值就会发生错误。
3.CACHE(缓冲)定义存放序列的内存块的大小,默认为20。NOCACHE表示不对序列进行内存缓冲。对序列进行内存缓冲,可以改善序列的性能。大量语句发生请求,申请序列时,为了避免序列在运用层实现序列而引起的性能瓶颈。Oracle序列允许将序列提前生成 cache x个先存入内存,在发生大量申请序列语句时,可直接到运行最快的内存中去得到序列。但cache个数也不能设置太大,因为在数据库重启时,会清空内存信息,预存在内存中的序列会丢失,当数据库再次启动后,序列从上次内存中最大的序列号+1 开始存入cachex个。这种情况也能会在数据库关闭时也会导致序号不连续。
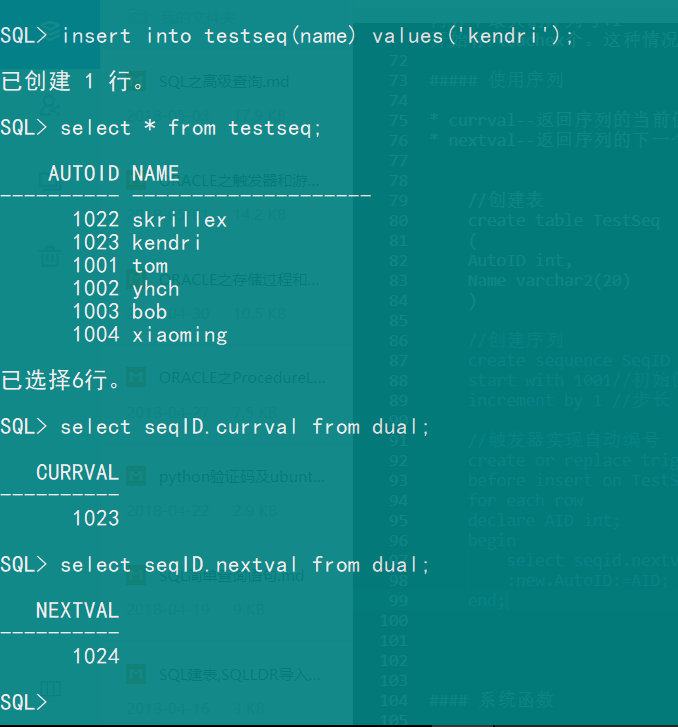
使用序列
- currval–返回序列的当前值
- nextval–返回序列的下一个可用值
1 | //创建表 |
PS
这里的序列出现断层(跳号),是什么原因?
其实这正好验证了上面的补充3,这个序列是我4天前为写触发器那篇博客定义的,现在我再次插入,预存在cache中的序列丢失了,默认cach中存放了20个序列,那为什么不是1021呢?,这里又涉及到导致跳号的另一个原因,因为我刚才写错了一条insert语句,因此序列有从1021,跳到了1022,我实验了几次发现确实是这样,发现错误的插入也会导致序列跳号,这可能是oracle的设计缺陷,也可能另有用处,但是即便如此,序列还是保证了唯一性
系统函数
字符串处理函数
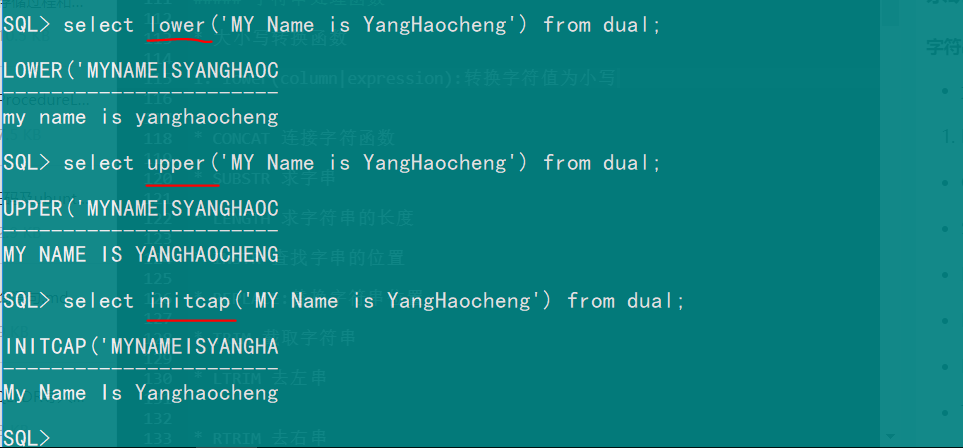
- 大小写转换函数
- lower(column|expression):转换字符值为小写
- upper(column|expression):转换字符值为大写
- initcap(column|expression):转换每个单词的首字母为大写,其他所有字母为小写
- CONCAT 连接字符函数
- 语法:concat(column1|expression,(column2|expression))
- 说明:和 || 等价
1 | select concat(studno,studname) from studinfo |
- SUBSTR 求字串
- 语法:substr (column1|expression,m,[n])
说明:
–第一个字符索引为1
–返回开始位置为m,长为n的字符串
–若m为负数,从字符串末尾开始计数
–若不指定n返回到字符串结束的所有字符

- LENGTH 求字符串的长度
- 语法:length(column1|expression)
- 说明: 返回字符数
1 | select length('oracle') from dual |
- INSTR 查找字串的位置
- 语法: (column1|expression,‘string’,[m],[n])
说明:
–返回一个字符串的数字位置。
– m作为查找的开始,在字符串中第n次发现的位置。
– m和n的默认值是1
1 | select instr('banana','b') from dual |
- REPLACE:替换字符串位置
- 语法:replace(text,search_string,replacement_string)
- 说明:在txt中,查找search_string,如果找到用replacement_string代替它
1 | select replace('my name is yanghaocheng','yanghaocheng','yhch') test from dual |
- TRIM 截取字符串
- 语法:trim(leading|trailing|both,trim_character from trim_source)
说明:
–从一个字符串修整头或尾字符(或两者)。
–-若trim_character或trim_source是字符,必须放在单引号中
–截取集只能有一个字符
1 | select trim('y' from 'yanghaocheng') test from dual |
- LTRIM 去左串
- 语法:ltrim(source_sting,trim_string)
- 说明: 从source_string最左边去除trimstring
1 |
|
- RTRIM 去右串
- 语法:rtrim(source_string,rtrim_string)
- 说明:从source_string最右边去除rtrim_string
1 | select rtrim ('yanghaocheng','cheng') from dual |
- LPAD,RPAD 填充字符串
语法:lpad/rpad(column1|expression,n,string)
说明: 填充字符值左、右调节到n字符位置的总宽度
- 小结
| function | result |
|---|---|
| concat(‘Hello’,’Word’) | HelloWord |
| substr(‘HelloWord’,1,5) | Hello |
| length (‘HelloWord’) | 10 |
| instr (‘HelloWord’,’w’) | 6 |
| trim(‘H’ from ‘HelloWorld’) | elloWord |
数字函数
ROUND(column|expression, n)
四舍五入列、表达式或值为n位小数位,或者,如果n被忽略,无小数位。(如果n是负值,小数点左边左边的数被四舍五入)
1 | select round(3.14,1) from dual //return 3.1 |
TRUNC(column|expression,n)
截断列、表达式或值到n位小数,或者,如果n被忽略,那么n默认为0
1 | select trunc(3.1415926) from dual //return 3 |
MOD(m,n)
返回m除以n的余数
1 | select mod(4,10) from dual //return 4 |
日期函数
Oracle 数据库用内部数字格式存储日期:世纪,年
,月,日,小时,分钟和秒默认日期显示格式是DD-MON-RR.
修改默认日期格式
– ALTER SESSION SET NLS_DATE_FORMAT =‘date format model’;
– 示例:
ALTER SESSION SET NLS_DATE_FORMAT=
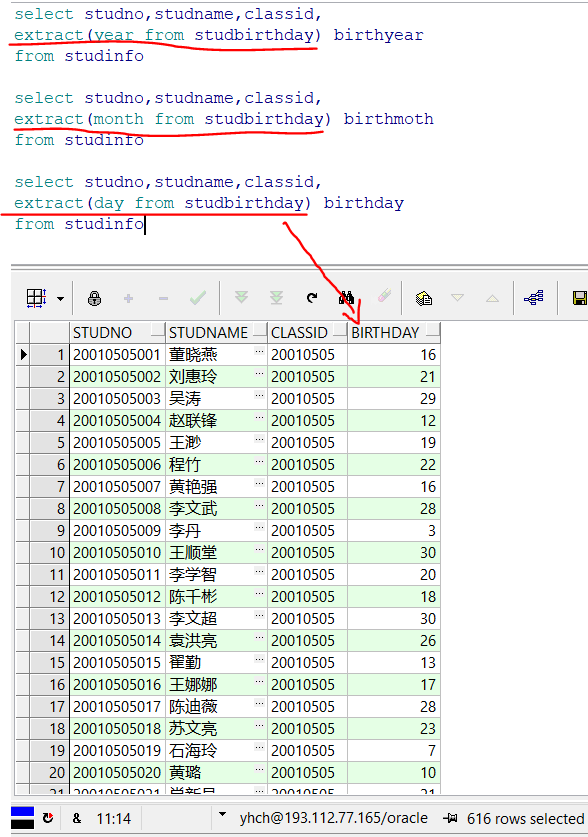
‘YYYY-MM-DD’extract
1 | 语法: extract(year/moth/day from studbirthday) |
表达式
1 | CASE WHEN boolean_expr1 THEN return_expr1 |
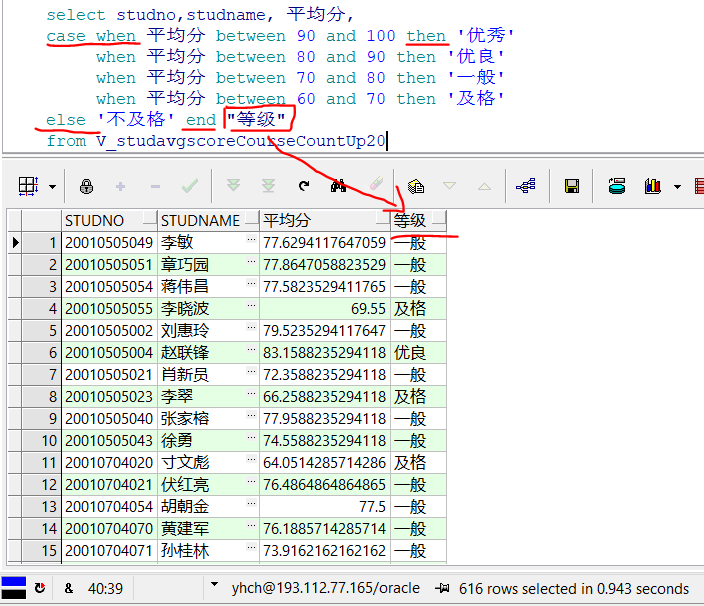
示列: 在学生成绩信息表(StudScoreInfo)和学生信息表(StudInfo)中将求出的平均分按以下等级输出。(包括学号,姓名,性别,出生日期,平均分,等级字段)
平均分 等级
90—100 ‘优秀’
80—90 ‘优良’
70—80 ‘一般’
60—70 ‘及格’
60 以下 ‘不及格’1
2
3
4
5
6
7select studno,studname, 平均分,
case when 平均分 between 90 and 100 then '优秀'
when 平均分 between 80 and 90 then '优良'
when 平均分 between 70 and 80 then '一般'
when 平均分 between 60 and 70 then '及格'
else '不及格' end "等级"
from V_studavgscoreCourseCountUp20
练习
- 找出平均分最高的前 10 个学生成绩统计信息(包括学号、平均分、课程门数)
1 | select studno,count (*)课程门数,avg(studscore)平均分 |
- 找出课程门数在 20 门以上的平均分最高前 10 个学生基本信息(包括学号、姓名、姓名、
班级编号、班级名称字段)
1 | create or replace view v_avgscoredesc as |
- 课程类别为 A、B、C、D11、D12 为基础课和专业课,即统称为学位课,请统计“电信
01”班的各学生学位课的平均分、总分、课程所修门数、最高分、最低分。
1 | create or replace View v_电信01同学成绩 as |
- 创建学生平均成绩视图(ViewStudAvgScore)其中包括学生学号、学生姓名、平均分、总
分 、 最 高 分 、 最 低 分 、 课 程 门 数 , 即
(StudNo,StudName,AvgScore,SumScore,MaxScore,MinScore, CountCourse)字段。
1 |
|
- 在视图(ViewStudAvgScore)中查询平均分在 80-85 和 60-70 之间的数据记录,其中包括学
生学号、学生姓名、班级名称、平均分、课程门数。
1 | select * from v_Studavgscore |
- 在视图(ViewStudAvgScore)中学生平均分大于 80 且课程门数为 30 门以上的男学生基本
信息,包括学号、姓名、性别、出生日期、班级、平均分、课程门数字段。
1 | select s.studno,s.studname,studsex,studbirthday,classid,avgscore,课程门数 |
- 创建一个序列(NewStudNo),初始值为 10001,步长为 1,最大值为 99999
1 | create sequence NewStudNo |
- 将农经 01 班的所有学生以题目 7 建立的序列号为学号存入新表
StudInfoSequence 中
1 | create table stuinfosequence as |
9.创建满足条件的学生平均分视图(ViewStudAvgScoreCourseCountUp20),如果课程门数大
于 20 门,则去掉最高分、最低分,剩下的课程求平均。如果课程门数小于等于 20 门,
则所有对所有课程求平均。其中包括学生学号、学生姓名、平均分、总分、最高分、最
低 分 、 课 程 门 数 , 即 (StudNo,StudName,AvgScore, SumScore,MaxScore,MinScore,
CourseCount)字段。
1 | create view V_studavgscoreCourseCountUp20 as |
- 在学生成绩信息表(StudScoreInfo)和学生信息表(StudInfo)中将求出的平均分按以下等级输出。(包括学号,姓名,性别,出生日期,平均分,等级字段)
平均分 等级
90—100 ‘优秀’
80—90 ‘优良’
70—80 ‘一般’
60—70 ‘及格’
60 以下 ‘不及格’
1 | select studno,studname, 平均分, |
- 统计“可视化程序设计”课程各分数段的人数,结果结构如下所示:
成绩 等级 人数
90—100 ‘优秀’ 66
80—90 ‘优良’ 90
70—80 ‘一般’ 84
60—70 ‘及格’ 80
60 以下 ‘不及格’ 19
1 | select * from courseinfo |
- 查询姓名为三个字,且以丽字结尾的学生成绩信息。(注:使用 Like 和函数 SubStr 两种
方法完成)
1 | A. |
- 将学生信息表中所有姓“刘”的学生更改成姓“牛”。
1 | update studinfo set studname = ('牛' || substr(studname,2)) |
- 找出相同性别且相同生日出生的学生。
1 | create view V_samesexsambir as |
- 找出出生日期为空值的学生平均分成绩信息。
1 | select studno,avg(studscore) 平均分 |
- 找出所有姓“王”的各学生平均分比所有姓“李”的各学生平均分高的学生成绩统计信
息。
1 |
|
小结
到目前为止,关于数据库的文章我打算告一段落(共计7篇文章),估计以后还会出关于数据库的文章,毕竟这些知识只是基础知识,也可能会出Mysql的博客,当时是为复习oracle而开始了第一篇文章的,像这样的一边博客我是要写5,6个小时的,如果算上之前的学习和练习,大概3天能出上这样一篇博客,虽然很消耗时间,但是我还是坚持了下来,计算机很多东西,我会弄,会做,但只是
知其然,但写博客就要求我知其所以然,它的原理是什么,这是我愿意坚持下去的原因之一。
投喂我
写文不易,如果本文对你有帮助,点击Donate,微信和支付宝投喂我