动态加载页面信息的提取 当我们浏览一个新闻类的网站,例如微博,今日头条,知乎等,由于它的内容极多,当我们搜索某一关键词的信息后,服务器只会向我们返回少量的数据,微博和头条是返回指定数量的数据,当我们再次向下刷新的时候,会再次通过Ajax请求返回指定数目的数据(如果你的网络不好时,会出现一个表示正在加载的小圆圈的动画效果)。知乎是当浏览器的滚动条触底时,再次提取数据。这就产生了一个问题,通过爬虫如何来提取通过Ajax请求动态加载的数据呢?
模拟Ajax请求 这时需要通过Chrome等浏览器的开发者工具,利用Chrome开发者工具的筛选功能筛选出所有的Ajax请求。选择network选项,直接点击XHR分析网页后台向接口发送的Ajax请求,用requests来模拟Ajax请求,那么就可以成功抓取信息了
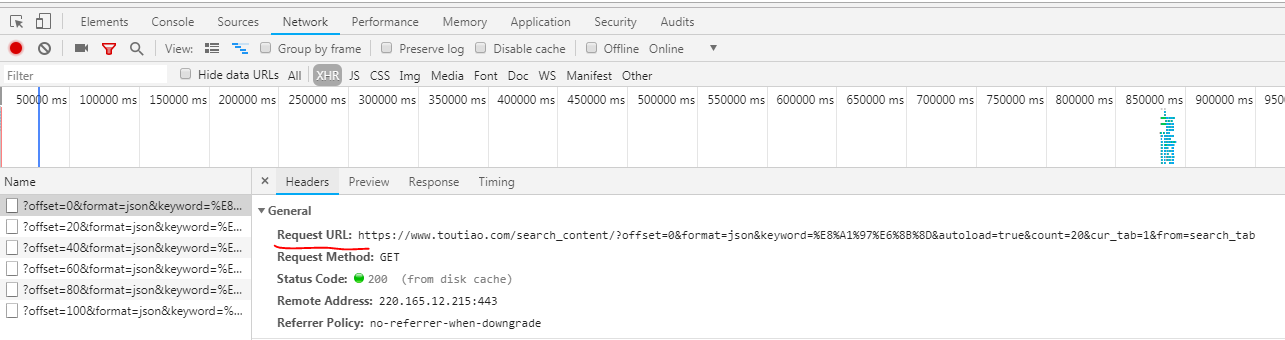
待爬取网站的Ajax请求的分析 这里选择今日头条来搞事情,通过爬虫来下载头条上的街拍图片,搜索关键词街拍,分析Ajax请求。下面是提取到的Ajax的主要信息
1 2 3 4 5 6 7 8 Request URL: https://www.toutiao.com/search_content/? offset=0& format=json& keyword=%E8%A1%97%E6%8B%8D& autoload=true& count=20& cur_tab=1& from=search_tab
1.分析请求 https://www.toutiao.com/search_content/ ? 号,之后的都是请求所带的参数
可以发现每加载一次内容参数offset 加20,表示偏移量,每次取20条数据
format 是不变的,表示格式是json格式的,
Keyword 是我们搜索的关键字%E8%A1%97%E6%8B%8D& ,,可能是中文的某种加密方式加密后的结果
发现offset 加20就可以了,其他参数照搬,因为都是不变的参数
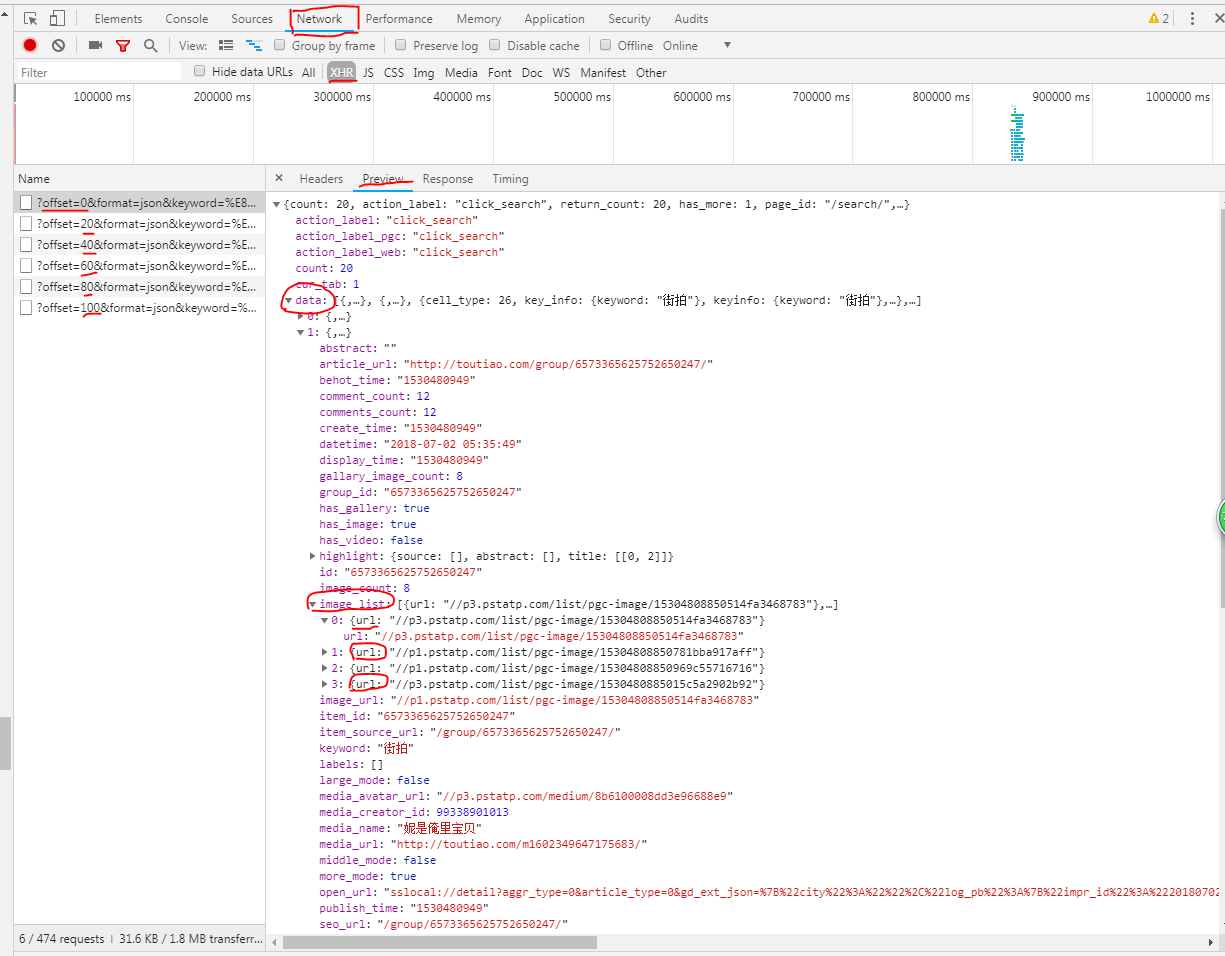
2.分析响应
代码实现
首先,实现方法get_page()来加载单个Ajax请求的结果。其中唯一变化的参数就是offset,所以我们将它当作参数传递,代码实现如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 import requestsfrom urllib.parse import urlencode def get_page (offset) : params = { 'offset' :offset, 'format' : 'json' , 'keyword' :'街拍' , 'autoload' :'true' , 'count' :'20' , 'cur_tab' :'1' , 'from' : 'search_tab' , } url = 'https://www.toutiao.com/search_content/?' + urlencode(params) try : r = requests.get(url) if r.status_code == 200 : return r.json() except : return None
Python内置的HTTP请求库,通常我们使用的是功能更为强大的requests 库,用到urllib 的parse工具模块,提供了许多URL处理方法,比如拆分、解析、合并等。用urlencode()方法构造请求的GET参数。
接下来,再实现一个解析方法:提取每条数据的image_list 字段中的每一张图片链接,将图片链接和图片所属的标题一并返回,同时构造一个生成器。实现代码如下:
1 2 3 4 5 6 7 8 9 10 11 def get_images(jsondata): if jsondata.get ('data' ): for item in jsondata.get ('data' ): title = item.get ('title' ) images = item.get ('image_list' ) for image in images: yield { 'image' : image .get ('url' ), 'title' : title }
接下来,实现一个保存图片的方法save_image(),其中item就是前面get_images()方法返回的一个字典。在该方法中,首先根据item的title来创建文件夹,然后请求这个图片链接,获取图片的二进制数据,以二进制的形式写入文件。图片的名称可以使用其内容的MD5值,这样可以去除重复。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 def save_image(item ): if not os.path.exists(item .get ('title' )): os.mkdir(item .get ('title' )) try : image_url = item .get ('image' ) print(image_url) r = requests.get ('http:' +image_url) if r.status_code == 200 : file_path = '{0}/{1}.{2}' .format (item .get ('title' ),md5(r.content).hexdigest(),'jpg' ) if not os.path.exists(file_path): with open (file_path,'wb' ) as f: f.write (r.content) else : print('Already Downloaded' , file_path) except: print('Faild to Save Image' )
最后,构造一个offset数组,遍历offset,提取图片链接,并将其下载:1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 def main(offset ): jsondata = get_page(offset ) for item in get_images(jsondata): print(item ) save_image(item ) num_start = 1 num_end = 20 if __name__ == '__main__' : pool = Pool() num = ([x * 20 for x in range(num_start,num_end + 1 )]) pool.map(main,num ) pool.close () pool.join()
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 import requestsfrom urllib.parse import urlencodeimport osfrom hashlib import md5from multiprocessing.pool import Pooldef get_page (offset) : params = { 'offset' :offset, 'format' : 'json' , 'keyword' :'街拍' , 'autoload' :'true' , 'count' :'20' , 'cur_tab' :'1' , 'from' : 'search_tab' , } url = 'https://www.toutiao.com/search_content/?' + urlencode(params) try : r = requests.get(url) if r.status_code == 200 : return r.json() except : return None def get_images (jsondata) : if jsondata.get('data' ): for item in jsondata.get('data' ): title = item.get('title' ) images = item.get('image_list' ) for image in images: yield { 'image' : image.get('url' ), 'title' : title } def save_image (item) : if not os.path.exists(item.get('title' )): os.mkdir(item.get('title' )) try : image_url = item.get('image' ) r = requests.get('http:' + image_url) if r.status_code == 200 : file_path = '{0}/{1}.{2}' .format(item.get('title' ),md5(r.content).hexdigest(),'jpg' ) if not os.path.exists(file_path): with open(file_path,'wb' ) as f: f.write(r.content) else : print('Already Downloaded' , file_path) except : print('Faild to Save Image' ) def main (offset) : jsondata = get_page(offset) for item in get_images(jsondata): print(item) save_image(item) num_start = 1 num_end = 20 if __name__ == '__main__' : pool = Pool() num = ([x * 20 for x in range(num_start,num_end + 1 )]) pool.map(main,num) pool.close() pool.join()
这里定义了分页的起始页数和终止页数,分别为num_start和num_end,还利用了多线程的线程池,调用其map()方法实现多线程下载
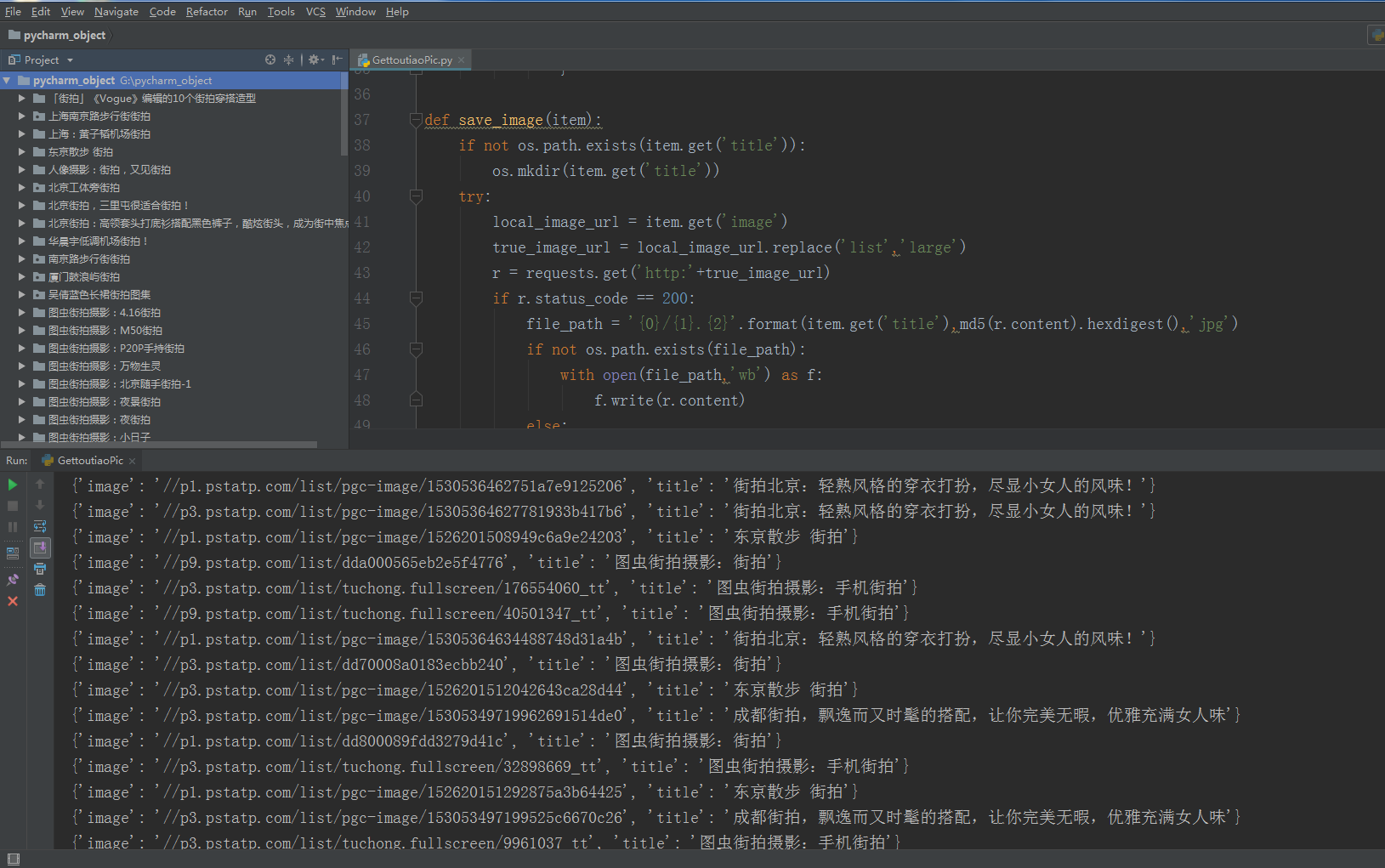
运行效果
投喂我 写文不易,如果本文对你有帮助,点击Donate,微信和支付宝投喂我